在前面中已经把爬取的数据存入到es,接下来就是进行前端和写es的分词规则和索引的步骤了(额,我是先创建django项目的)
创建django项目
先给出我的项目目录结构吧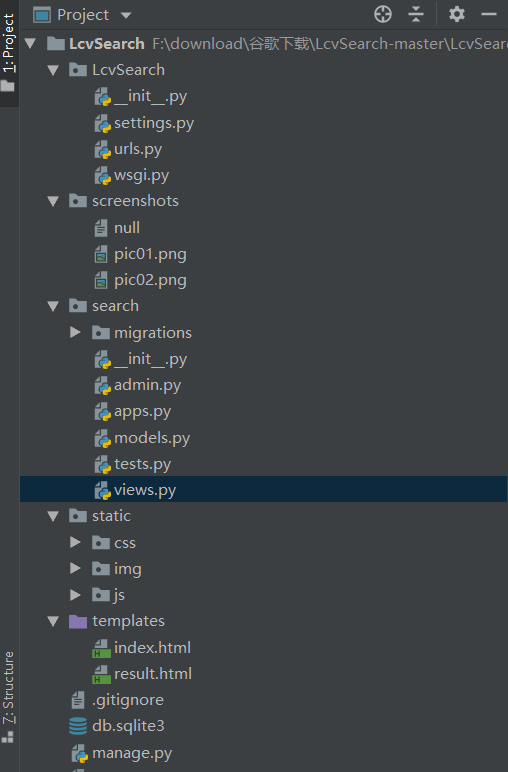
一、写es分词和索引规则
1 | response = client.search( |
对数据进行处理
1 | for hit in response["hits"]["hits"]: # 对查询的数据进行处理 |
二、编写前端页面并进行数据的接入工作
这里主要是对urls和views这两个文件进行操作
urls
1 | from django.conf.urls import url |
views.py
1 | import json |
对了,在search的目录先也要创建一个modes把前面es_type的代码拷过去就行了(作用跟之前的一样)
前端的页面如下:
搜索页面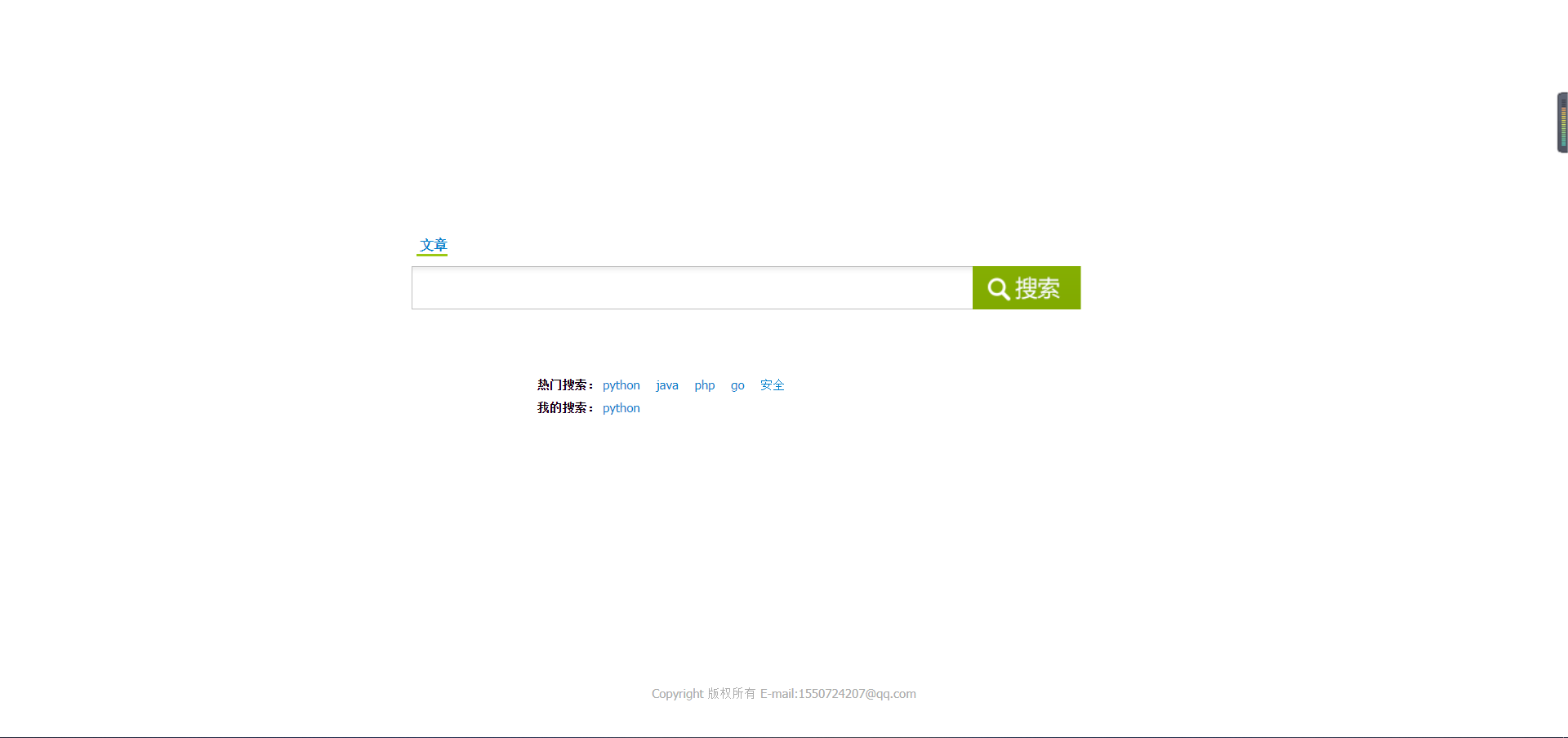
结果页面
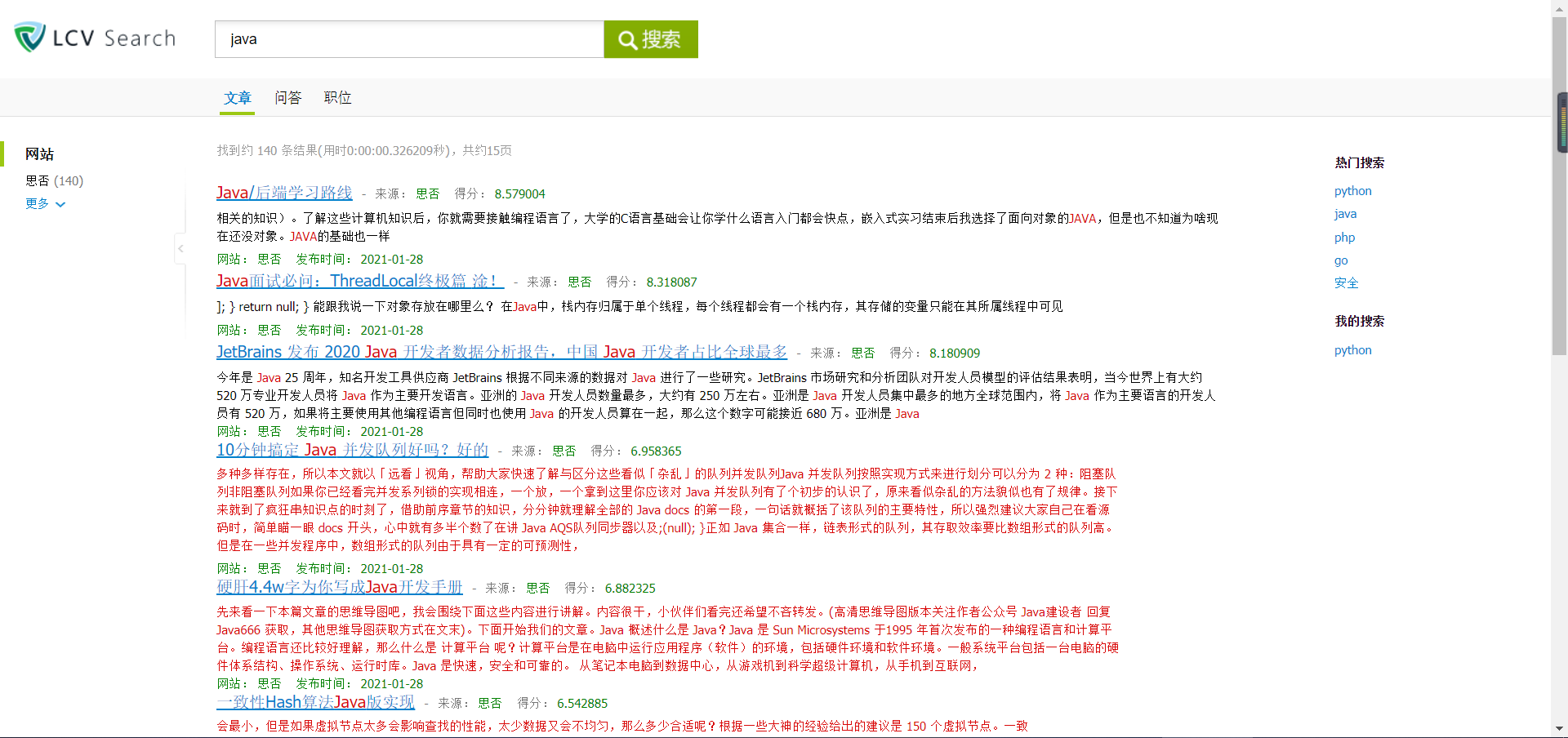
额,前端的源码就不在这展示了,感觉好费(就是懒…)到时候我会上传GitHub,这里主要是把步骤,关键的部分提一下 通过传入的数据用js实现我的搜索
1 |
|
通过redis的zrevrangebyscore函数计算分值的方式,以分值高的为热门来实现热门搜索
1 | class IndexView(View): |
总结
熟悉了打造搜索引擎的流程及相关的知识,对request、response、post、get等知识有了一定的理解.不过这只是爬取了一个网站的信息,后期的话有了第一个可以慢慢来增加都行.
效果展示