前言
我们上网用得最多的一项服务应该是搜索,都喜欢百度一下或谷歌一下, 那么百度和谷歌是怎样从浩瀚的网络世界中快速找到你想要的信息呢(好奇吧) 这就是搜索引擎的魅力,一个信息检索的领域。
打造搜索引擎的方式
打造搜索引擎有几种方式,介绍我了解过的两种
搜索引擎的几个要点:
- 一个强大的爬虫(数据库)资源和服务器支持
- 分词(jieba)、索引(whoosh)。这里用的是es是企业级的搜索引擎集合了分词和索引;许多大厂都在用比如github、facebook等
- 数据的展示和接入(这里用的是django)
第一步,爬虫的准备工作
这里是用scrapy的框架进行爬取的,scrapy的安装只需pip install scrapy(只需要你安装好Python→_→) 创建项目:scrapy statproject "你的项目名" scrapy genspider "爬虫名" "爬取目标网站的域名"
额……具体怎么爬就不说了,接下来介绍踩的坑:
1、settings的设置
2、缩进问题,Python对这个很严谨,然后因为scrapy是对多个文件的操作。。。如果你在某个需要缩进的没有缩进,而那个刚好在一个函数下面→_→就没那么好搞了特别是一段的时候(虽然会报错定位到哪一行)
以下是我爬取思否的源代码:
1 | # -*- coding: utf-8 -*- |
二、es的介绍及应用
es讲真我也不算是很了解但是在打造引擎所用到的倒是还是有多了解的。 es在打造引擎扮演的角色中你可以把它当做一个数据库、可以是一个强大分词和索引。接下来也是应用这几个功能来说明。
es的下载安装:es下载
这里有两个我踩过的坑,得注意一下
- 提示 python.lang.ClassNotFoundException,在包里有个lang.py的文件删掉它
- 得用管理员权限运行es
对了,还有一个跟es的搭配的可视化es-head下载
重点来了
在存入es中的时候,需要设置每个字段的类型(具体可以看看一些博客,或者官方文档,还挺简单理解的),所以需要在项目目录下创建一个modes文件夹该文件下创建es_type.py如图:
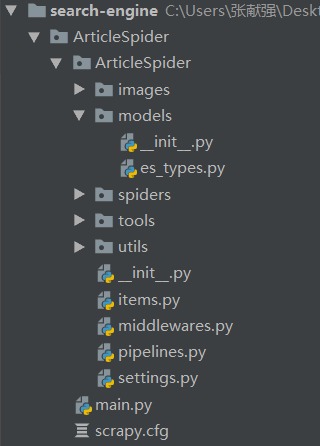
源代码如下:
es_types
1 | from datetime import datetime |
items
1 | import datetime |
pipelines
1 | class ElasticsearchPipeline(object): |
settings
1 | ITEM_PIPELINES = { |
到这里就把数据存入了es了,可以通过es-head可视化来查看存入情况
嗯......这里,我好像也没遇到啥,坑太深的,嗯,就是在es_type.py的编写,一定要严格遵守它的语法就没什么大问题,哦,对了...版本问题一定得注意。(报错的信息,找到错误的准确信息然后复制Google一下多找找一般能找到解决办法)
这里推荐几个博客
有关新闻的搜索引擎的SduViewWebSpider